Splunkに入門した
Oct 21, 2023 01:30 · 1841 words · 4 minute read
Splunkに入門しました。 まずは基礎的な内容を学んだので、復習用にBlogに記録しておきます。
目次
Splunkの構成要素
Forwarder
ログなどのデータを収集してIndexerに送信します。
Universal Forwarder(UF):
軽量なForwarderです。データの転送だけしたい場合に使います。
Heavy Forwarder(HF):
データを転送するだけでなく、データの変換やフィルタリングなど、追加の操作をしたい場合に使います。
Indexer
Forwarderからデータを受け取り、検索可能な状態に変換して保存します。 データを保存するだけでなく、高速にデータを検索するためのIndexを作成します。
複数のIndexerをクラスタリングしてスケーラビリティを確保することもできます。 また、それぞれのIndexerで相互にデータの複製を保持することで、完全性の確保にも役立ちます。
Search Head
ユーザがデータを検索し、視覚化するためのインターフェースを提供します。 ユーザーは検索クエリをSearch Headに送信し、Search HeadはクエリをIndexerに送信して結果を受け取ります。 Search Headは受け取った結果をユーザに表示します。 結果を表示するだけでなく、グラフや表を使った視覚化やダッシュボードの作成にも使えます。
デプロイメントモデル
規模に応じていくつかのデプロイメントモデルがあります。 代表的な導入シナリオは下記の4つです。
- Departmental
- Small enterprise
- Medium enterprise、Large enterprise
- High availability
Departmental
IndexerとSearch Headを1つのインスタンスで実行する構成です。
- インデックス作成量は 20GB/日未満
- Userは10人未満
- 少数のForwarderがIndexerにデータを渡す(100が上限?100を超えても動作する?)
という構成です。

参照: Departmental deployment: Single indexer - Splunk Documentation
Small enterprise
1つのSearch Headと2-3のIndexerを組み合わせた構成です。 Small enterprise以降はマルチインスタンスで展開します。具体的には、Search HeadとIndexerを別のマシンで実行する別のインスタンスに割り当てます。
- インデックス作成量は 20GB/日未満
- ユーザー数は 10 ~ 100 人
- 最大数百のForwarderがIndexerにデータを渡す(明確な数の制限は無さそう)
という構成です。
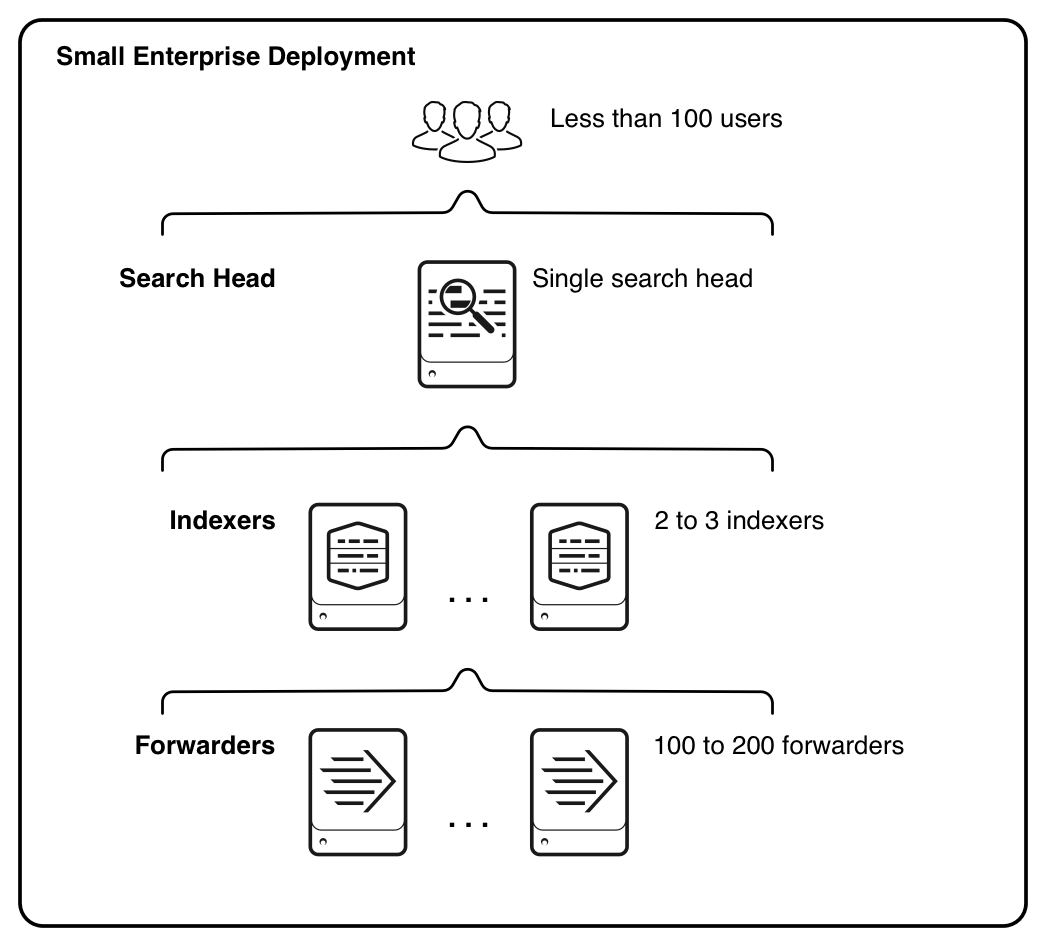
参照: Small enterprise deployment: Single search head with multiple indexers - Splunk Documentation
Medium enterprise、Large enterprise
複数のSearch Headと複数のIndexerを組み合わせた構成です。 必要に応じてSearch HeadとIndexerの数を増やします。
- インデックス作成量は 100 ~ 300 GB/日
- ユーザーの数は 100 人以上(明確な制限は無さそう)
- 最大数千のForwarderがIndexerにデータを渡す(明確な制限は無さそう)
という構成です。
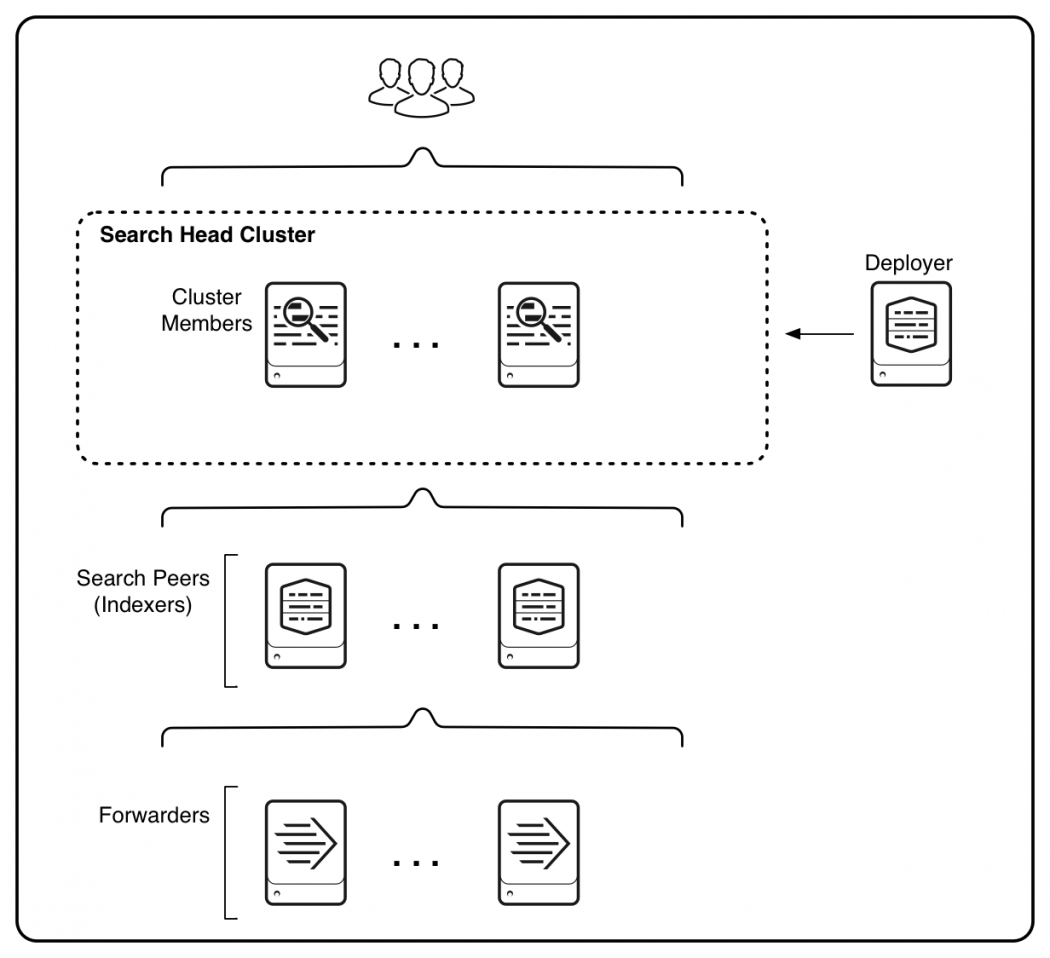
High availability
Indexer clusterを構成します。Indexerが相互にデータを複製する信頼性の高い構成です。 データの複製を作るので、単に複数のIndexerを使うよりも多くのストレージが必要です。
Indexerだけではなく、Search Headも複数台組み合わせて使います。 データの複製を作らずにIndexer clusterを使うことも可能です。
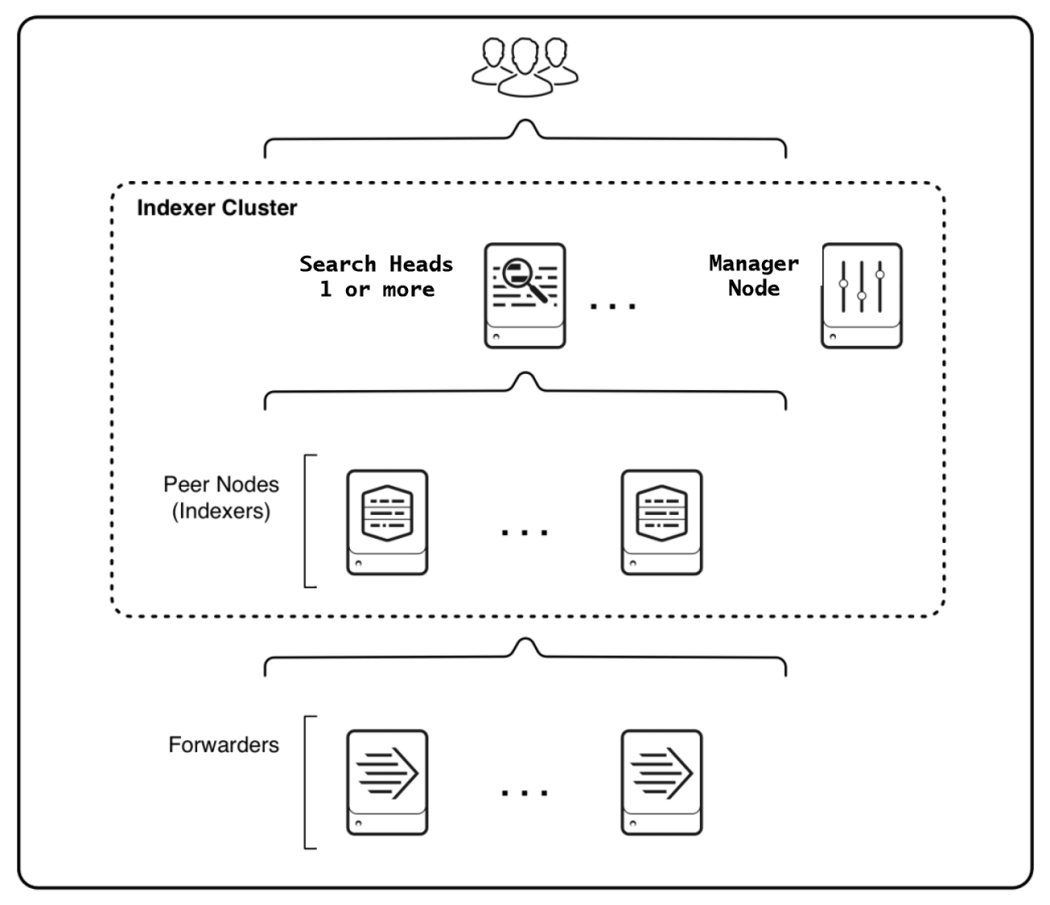
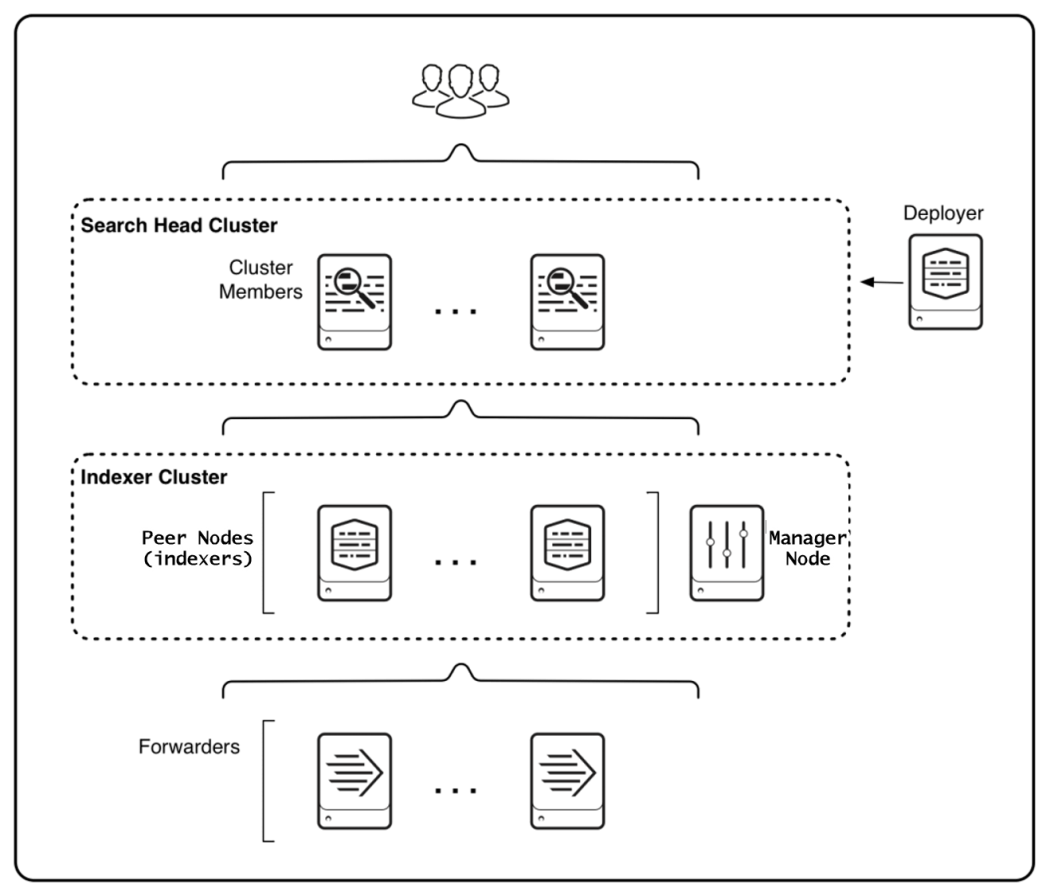
参照: High availability deployment: Indexer cluster - Splunk Documentation
比較表
規模別のデプロイメントモデルの比較です。
Types of distributed deployments - Splunk Documentation
SPL
Splunkでは、SPL(Splunk Processing Language)というクエリ言語を使います。 SPLによって、データを検索・集計・加工します。
サンプル
index="_internal" sourcetype="splunkd" source="*/splunkd.log"
| eval log_level_head = substr (log_level, 1, 1)
| stats count BY log_level_head
| table log_level_head, count
| rename log_level_head AS "ログレベル", count AS "件数"
| head 10
下記のquick reference guideが便利です。
また、ChatGPTに大まかなSPLを作ってもらい、その後自分で微調整する方法がとても便利でした。
DockerでSplunkを動かす
OSとCPUの制限はありますが、DockerでSplunkを動かすこともできます。
splunk/splunk - Docker Image | Docker Hub
DebianベースのOSとx86-64をサポートしているので、WindowsのWSL2でも動くようです。
HayabusaとSplunkによるファストフォレンジック効率化: NECセキュリティブログ | NEC
最後に
Splunkを使い始めたので、学んだことを整理しました。 次はダッシュボードを作ってみようと思います。
Create and customize dashboards — Splunk Observability Cloud documentation