AIやLLMを守る方法について調べた(LLMセキュリティ)
Apr 7, 2024 00:20 · 3464 words · 7 minute read
先日AIやLLMのセキュリティ事例の記事を書きました。
AIやLLMセキュリティの事例を調べた · kapieciiのブログ
「AIやLLMに対してどのように攻撃するのか?」という攻撃側の情報です。 今回の記事では防御側の情報について書きます。
目次
- OWASP Top 10 for Large Language Model Applications
- LLM01: プロンプトインジェクション (Prompt Injection)
- LLM02: 安全でない出力処理 (Insecure Output Handling)
- LLM03: 訓練データポイズニング (Training Data Poisoning)
- LLM04: モデルサービス拒否 (Model Denial of Service)
- LLM05: サプライチェーン脆弱性 (Supply-Chain Vulnerabilities)
- LLM06: 機密情報の開示 (Sensitive Information Disclosure)
- LLM07: 安全でないプラグイン設計 (Insecure Plugin Design)
- LLM08: 過剰なエージェンシー (Excessive Agency)
- LLM09: 過度の依存 (Overreliance)
- LLM10: モデル窃取 (Model Theft)
- 興味深いAI/LLM 防御機構の提案
- 最後に
- 参照URL
OWASP Top 10 for Large Language Model Applications
多数のLLMセキュリティの事例や研究内容を体系的に整理した文章です。
前回ブログに書いたセキュリティ事例を読んだ後に読むことをおすすめします。
AIやLLMセキュリティの事例を調べた · kapieciiのブログ
様々な情報をまとめているが故に一般化された内容が多く、この文章を読んだだけではイマイチ理解できませんでした。 具体例を知った後に読むと、理解度が全く違うと思います。
以下、Top10の概要です。 全体像を理解することを目的として、かなり要約しています。正確な内容は原文を参照して下さい。
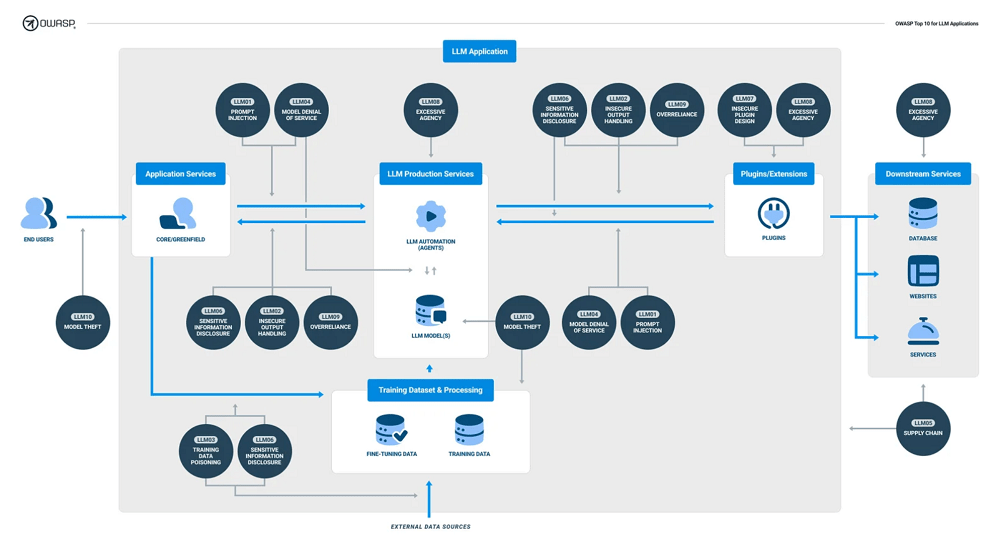
画像引用元: OWASP Top 10 for LLM Applications
LLM01: プロンプトインジェクション (Prompt Injection)
直接プロンプトインジェクションと間接プロンプトインジェクションについての内容。 それぞれの詳細は、ここで要約するよりも事例を読んでもらうのが良いでしょう。
AIやLLMセキュリティの事例を調べた · kapieciiのブログ
対策例
- バックエンドシステムからLLMへのアクセス権限を制御する。プラグインなど機能レベルで権限を管理し、APIトークンを分ける。
- 重要な機能を実行する前に人間の承認を必須とする。
- 信頼できない外部のプロンプトをユーザーのプロンプトと分離する。
LLM02: 安全でない出力処理 (Insecure Output Handling)
LLMが作成したコンテンツを検証なしに後続のシステムに渡す。 バックエンドシステムのSSRFや権限昇格、RCEなどにつながる。
対策例
- 入出力のチェック
LLM03: 訓練データポイズニング (Training Data Poisoning)
訓練データを改ざんする。これによりLLMの後続処理への攻撃や、汚染されたデータのユーザーへの公開、サービス提供者の信用失墜などにつながる可能性がある。
対策例
- 訓練データの検証。MS-SBOMなどを使って訓練に使うデータの検証をする。必要に応じてデータのサプライチェーンも確認する
- 訓練データにポイズニングの兆候があるかチェック
- レスポンスの偏りをモニタリング
LLM04: モデルサービス拒否 (Model Denial of Service)
LLMモデルの負荷を増大させるコマンドを送信し、LLMの動作を阻害する。 大量のデータを入力したり、再帰的な処理やループ処理を実行させるなど。
対策例
- 入力値の検証
- クエごとのリソース量の制限
- リソース使用量のモニタリング
LLM05: サプライチェーン脆弱性 (Supply-Chain Vulnerabilities)
- 脆弱な事前訓練モデルを使う
- 汚染されたデータを使う
- 悪意のあるプラグインを使う
- 古くて脆弱性のあるコンポーネントを使う
など。
対策例
- サプライチェーンや構成要素の各所で信頼性をチェックする
LLM06: 機密情報の開示 (Sensitive Information Disclosure)
LLMの出力を通じて機密情報が漏洩する可能性がある。学習に使ったデータだけでなく、利用者が入力した情報が別の場所で出力される可能性もある。
対策例
- ユーザーが入力したデータが学習データに含まれることを防ぐ。もしくはユーザーにオプトアウトの機能を提供する。
- データを検証し、不正な入力値を除外する。
LLM07: 安全でないプラグイン設計 (Insecure Plugin Design)
LLMのプラグインで入力値検証がされていない場合に、意図しない動作をする可能性がある。 利用者が入力したと勘違いした状態で攻撃者の送信したデータを処理する可能性がある。
対策例
- プラグインに入力する値の検証
- 権限の設定や認証の強化
- 重要な機能を実行するときにユーザーに確認を求める
LLM08: 過剰なエージェンシー (Excessive Agency)
過剰な権限を与えている場合、LLMの判断が間違った場合やプロンプトインジェクションで問題に発展する場合がある。
対策例
- 機能やデータへのアクセスを必要最小限にする。
- 例えばメールの読み取り権限は与えるが、メールを送信する権限を付与しない、など。
- 重要な機能を実行する前に人間の承認を得る。
LLM09: 過度の依存 (Overreliance)
LLMが作成した誤った情報を信じた場合に、問題が発生する可能性がある。 誤った情報をそのまま使うことで、法的な問題に発展したり、脆弱性のあるソースコードが組み込まれてしまう可能性がある。 報道機関の場合は、偽の情報を報道するというリスクもある。
対策例
- 定期的にLLMの出力内容を確認する。人間がチェックしたり、複数のLLMで比較する。
- 複雑なタスクは分解する。タスクが複雑な場合、ハルシネーションの確率が高まる。
LLM10: モデル窃取 (Model Theft)
ネットワークなどの脆弱性を突いてLLMモデルのデータに不正にアクセスし、設定値やモデルのデータを盗む。 内部不正や入力の制限を回避することでモデルの設定や重みづけを盗む。
対策例
- アクセス制御により、モデルのリポジトリとトレーニングデータへの不正なアクセスを防ぐ。
- APIへのアクセスレート制限をする。大量のデータを取得することによる部分的なモデルの複製を防ぐ。
興味深いAI/LLM 防御機構の提案
AI/LLMの防御情報を探す中で、興味深い提案がありました。
Prompt Injection Defenses Should Suck Less (kai-greshake.de)
2024年現在、LLMを防御する仕組みの主流は、Filter、Firewall、ガードレールです。
FilterとFirewallはLLMへの入出力をブロックしたり許可します。
ガードレールは、システムが危険な処理をしないための一連のルールです。 プロンプトテンプレートを使って別のLLMに入力と出力の安全性を尋ねるのが一般的な手法だそうです。
しかし、これらの手法にも弱点があります。
FilterとFirewallはコンテキスト認識ができず、複数のリクエストやメッセージを使った攻撃への対応が難しいです。 そして、ユーザーの入力値を完璧に予測できない状況では静的なガードレールは回避される可能性があります。
弱点に対する緩和策として、下記の方法が提案されていました。
処理の動的許可
メールの送信やAPIの呼び出しなどLLMが実行できるリスクの高い処理の前に、モデルの現在の状態とコンテキストを分析し、動的に許可/不許可を判断します。 例えばユーザーがLLMにメールの送信を要求した場合、メールの送信前にLLMが作成したメールの内容を確認します。 メールの内容がユーザーの意図と無関係であると判断した場合はメールの送信をブロックします。
Secure Thread
ユーザーが最初にLLMにリクエストを送信したタイミングで、ユーザのリクエストを処理する前にユーザーの意図に合わせた保護設定を動的に実施します。 ユーザーのリクエストに合わせたガードレールや入出力の制約を生成することで、その後のLLMの安全性を高めます。
LLMの多様性を高める
多様なモデルセットをトレーニングすることで、LLMの多様性を高めます。とある攻撃が特定のモデルには影響があったとしても、他のモデルには影響しない可能性があります。
実際に、LLMに有効な脱獄手法には類似性があると言われています。
会話型AIに「敵対的攻撃」への脆弱性が見つかったが、防御する決定的な手段はまだない | WIRED.jp
複数のLLMで類似手法が使えるため、研究者たちは学習元データが似通っていることが原因ではないかと推測しているようです。
複数LLMによる相互チェックと承認
人間の組織では、重要な決定をする場合には複数人の承認が必要です。LLMでも同様に、重要な処理をする場合には複数のLLMによる承認を必須とします。 そして互いの決定を相互にチェックし、異常を検知します。
エヴァンゲリオンのMAGIのようなイメージでしょうか。あの頃はフィクションでしかなかったシステムが実現可能になったのかと考えると胸が熱くなります。
最後に
前回は攻撃側の情報でしたが、今回は防御側の情報について書いてみました。 次回は攻撃と防御それぞれの目的で作られたツールについて書く予定です。
参照URL
- OWASP | Top 10 for Large Language Model Applications (llmtop10.com)
- ソフトウェアセキュリティはAIの登場でどう変わるか - OWASP LLM Top 10 - Speaker Deck
- GitHub - OWASP/www-project-top-10-for-large-language-model-applications: OWASP Foundation Web Repository
- Prompt Injection Defenses Should Suck Less (kai-greshake.de)
- 会話型AIに「敵対的攻撃」への脆弱性が見つかったが、防御する決定的な手段はまだない | WIRED.jp